
发布日期:2024-11-05 10:26 点击次数:109
IT之家 11 月 3 日消息,中国电信人工智能研究院(TeleAI)在今年 5 月发布业内首个支持 30 种方言自由混说的语音识别大模型 —— 星辰超多方言语音识别大模型。
时隔不到半年,TeleAI 星辰语音大模型的多方言能力再次升级,攻克了湛江话、宜宾话、洛阳话、烟台话等方言,将方言种类从 30 种提升至 40 种,并引入对英文的识别。
与传统的有标注训练方法相比,TeleAI 通过预训练语音识别模型,利用海量无标注数据进行预训练,再通过少量有标注数据进行微调。
由于方言语音数据普遍存在无标注数据多而有标注数据少的特点,这种“预训练 + 微调”的模型方案与方言场景的需求能够高度契合。
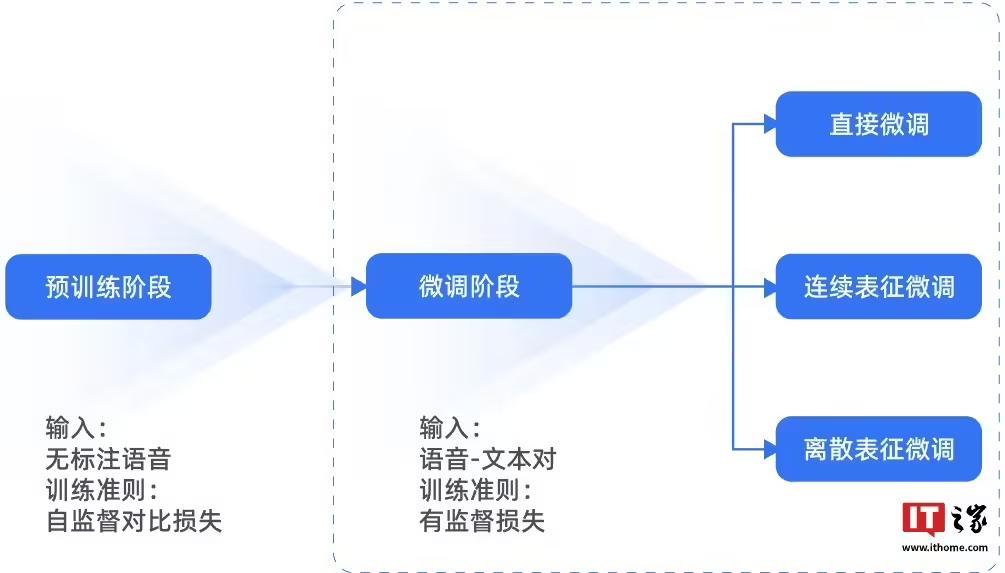
TeleAI 还在模型结构和成本优化上进行了创新,实现对人工标注数据的需求量大幅降低约 50 倍,且保障模型效果与有监督训练的方言模型水平相当。
IT之家附 GitHub 开源地址:https://github.com/Tele-AI/TeleSpeech-ASR
上一篇:#nova13多焦多自在# 华为nova 13 Pro的影像表现非常
下一篇:没有了